
Você está aqui: Home ‣ Dive Into HTML5 ‣
❧
 sse capítulo
pegará uma página HTML a qual não há nada de errado e irá
melhorá-la. Algumas partes ficarão menores, outras partes maiores. Tudo
isso ficará com uma melhor semântica. E ficará incrível.
sse capítulo
pegará uma página HTML a qual não há nada de errado e irá
melhorá-la. Algumas partes ficarão menores, outras partes maiores. Tudo
isso ficará com uma melhor semântica. E ficará incrível.
Esta é a página em questão. Abra a página em uma nova aba e não volte até dar uma olhada no código fonte pelo menos uma vez.
❧
A partir do topo:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Esse é o chamado “doctype.” Há uma longa história por trás do doctype. Enquanto trabalhavam no Internet Explorer 5 para Mac, os desenvolvedores da Microsoft depararam-se com um problema. A próxima versão do browser tinha melhorado tanto seus padrões, que páginas antigas não eram mais apresentadas corretamente. Ou até eram apresentadas (de acordo com as especificações), mas eles esperavam que fossem apresentadas incorretamente. Essas páginas foram criadas baseadas nas peculiaridades dos browsers que dominavam na época, como Netscape 4 e o Internet Explorer 4. O IE5/Mac estava tão avançado que acabou quebrando a web.
A Microsoft apareceu com uma nova solução. Antes de renderizar uma página,
o IE5 verificava o “doctype,” que geralmente era a primeira linha do
código HTML (até mesmo antes do próprio elemento
<html>). Páginas antigas (que seguiam os padrões dos
browsers antigos) geralmente não tinham o doctype. O IE5 renderizava essas
páginas como os browsers antigos faziam. Para ativar os novos padrões, os
autores das páginas web tinham que optar por inserir o doctype antes do
elemento <html>.
Essa idéia se espalhou como fogo, e logo, todos os principais browsers passaram a ter duas opções de interpretação: “modo peculiar (quirks mode)” e “modo padronizado (standards mode)”. É claro que, tratando-se da web, as coisas rapidamente perderam o controle. Quando a Mozilla tentou enviar a versão 1.1 de seu browser, eles descobriram que haviam páginas sendo apresentadas no “modo padronizado” que na verdade dependiam de uma peculiaridade específica. A Mozilla tinha acabado de corrigir sua rendering engine para eliminar essa peculiaridade, mas milhares de páginas quebraram de uma vez. Então foi criado — e não estou inventando isso — “o modo quase padronizado (almost standards mode).”
Neste trabalho seminal, Activating Browser Modes with Doctype, Henri Sivonen resume os diferentes modos de renderização:
- Quirks Mode (Modo peculiar)
- No Quirks mode, os browsers violam as especificações da web contemporânea para evitar “quebrar” páginas criadas de acordo com as práticas que prevaleciam no anos 90.
- Standards Mode (Modo padrão)
- No Standards mode, os browsers tentam, conforme os documentos da especificação, tratar corretamente a extensão implementada para um browser específico. Para o HTML5 este é o “quirks mode.”
- Almost Standards Mode (Modo quase padrão)
- Firefox, Safari, Chrome, Opera (a partir da versão 7.5) e o IE8 também possuem o modo conhecido como “modo quase padrão”, que implementa o dimensionamento vertical das células de tabelas tradicionalmente e não rigorosamente de acordo com a especificação CSS2. Para o HTML5 este é o “limited quirks mode.”
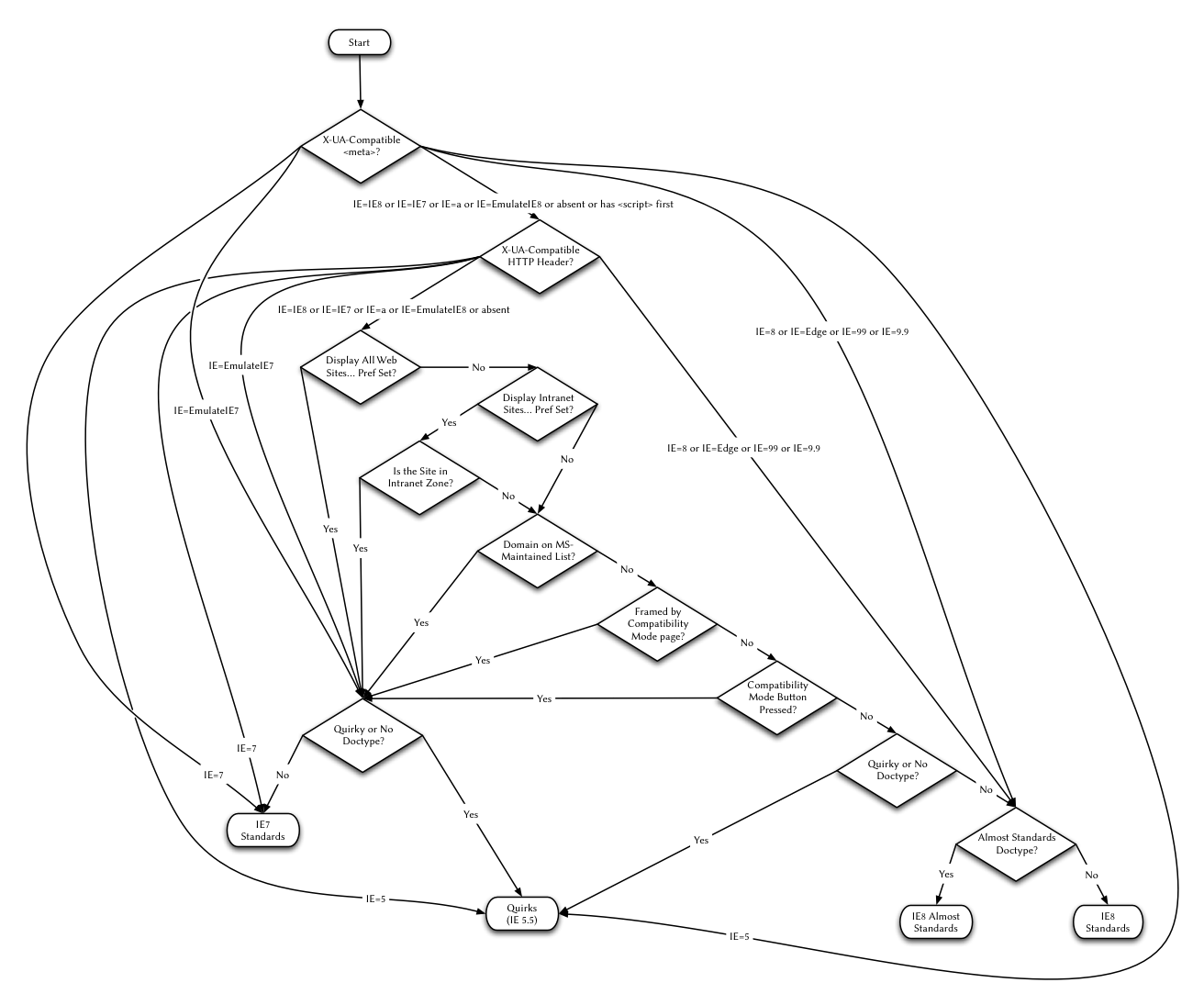
(Você deveria ler o resto do artigo de Henri, pois estou apenas simplificando aqui. Até no IE5/Mac, haviam alguns doctypes antigos que não contavam como opção padronizada. Ao longo do tempo, a lista de peculiaridades cresceu, assim como a lista de doctypes que as desencadeava. A última vez que tentei contar, haviam 5 doctypes que disparavam o “almost standards mode,” e 73 que disparavam o “quirks mode.” Mas provavelmente esqueci de alguns e não vou nem falar sobre a besteira que o Internet Explorer 8 faz para trocar entre seus quatro, — quatro! — diferentes modos de renderização. Este é o diagrama de fluxo. Mate-o e queime-o.)
Agora onde estavamos? Ah sim, o doctype:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Este passa a ser um dos 15 doctypes que disparam o “standards mode” em todos os browsers atuais. Não há nada de errado com ele. Se você gosta dele, pode ficar. Ou você pode mudá-lo para o doctype do HTML5, que é menor e melhor, e também dispara o “standards mode” em todos os browsers atuais.
Este é o doctype do HTML5:
<!DOCTYPE html>É só isso. Apenas 15 caracteres. É tão fácil que você pode digitá-lo na mão sem medo de errar.
❧

Uma página HTML consiste em uma série de elementos. Toda sua
estrutura é como uma árvore. Alguns elementos são “irmãos,” como dois
galhos que extendem-se de um mesmo tronco. Alguns podem ser “filhos” de
outros elementos, como um galho menor que extende-se de um maior. (Também
funciona de outro jeito; um elemento que contém outro elemento é chamado
de nó “pai” de seus elementos filhos, e o “antecessor” de seus elementos
netos). Elementos que não possuem filhos são chamados de nós “folha”. O
elemento mais externo, o qual é o antecessor de todos os outros elementos
da página, é chamado de “elemento raiz.” O elemento raiz de uma página
HTML é sempre o <html>.
Nessa página de exemplo, o elemento raiz se parece com isso:
|
Não há nada de errado com esta implementação. De novo, se você gosta dela, pode ficar. É válido no HTML5. Mas algumas partes não são mais necessárias no HTML5, então você pode economizar alguns bytes ao removê-las.
A primeira coisa a se discutir é o atributo xmlns. É um
vestígio do
XHTML 1.0. Ele
serve para saber que os elementos da página estão dentro do namespace
XHTML, http://www.w3.org/1999/xhtml. Mas os
elementos no HTML5
estão sempre neste namespace, sendo que você não precisa mais declará-lo explicitamente. Sua página
HTML5 funcionará exatamente igual em todos os browsers, este
atributo estando ou não presente.
Descartando o atributo xmlns, ficamos com este elemento raiz:
<html lang="en" xml:lang="en">
Estes dois atributos, lang e xml:lang, definem a
língua da página HTML. (en significa “Inglês.”
Não escreve em inglês?
Encontre sua língua.) Mas porque dois atributos para a mesma coisa? De novo, isso é um
vestígio do XHTML. Apenas o atributo lang tem
algum efeito no HTML5. Você pode deixar o atributo
xml:lang se preferir, mas se deixá-lo, deve garantir que ele
contenha o mesmo valor do atributo lang.
Para facilitar a migração do XHTML, devemos especificar um atributo sem namespace, sem prefixo e com o localname "xml:lang" nos elementos HTML de documentos HTML, mas estes atributos devem apenas serem especificados se o atributo
langtambém for especificado sem namespace. Os dois atributos são case-insensitive e devem conter o mesmo valor. O atributo sem namespace, sem prefixo e com o localname "xml:lang" não tem efeito no processamento da língua.
Está pronto para descartá-lo? Tudo bem, deixe-o ir. Indo, indo… já era! Isso nos deixa com este elemento raiz:
<html lang="en">E isso é tudo que tenho para falar sobre isso.
❧

O primeiro filho do elemento raiz geralmente é o elemento
<head>. O <head> contém informações
—metadata sobre a página, em vez do próprio corpo da
página. (O corpo da página fica no elemento <body>). O
elemento <head> é um pouco chato, e não mudou nada de
interessante no HTML5. A parte boa é o que está
dentro do <head>. E para isso, usaremos
novamente nossa
página de exemplo:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>My Weblog</title>
<link rel="stylesheet" type="text/css" href="style-original.css" />
<link rel="alternate" type="application/atom+xml"
title="My Weblog feed"
href="/feed/" />
<link rel="search" type="application/opensearchdescription+xml"
title="My Weblog search"
href="opensearch.xml" />
<link rel="shortcut icon" href="/favicon.ico" />
</head>Primeiramente: O elemento <meta>.
❧
Quando você pensa em “texto,” provavelmente pensa em “caracteres e símbolos que vejo na tela do meu computador.” Mas os computadores não lidam com caracteres e símbolos, mas sim com bits e bytes. Cada pedaço de texto que vê na tela de seu computador, é na verdade armazenado em uma codificação de caracteres (character encoding). Há centenas de character encodings diferentes, alguns otimizados para algumas línguas em particular como russo, chinês ou inglês, e outras que podem ser utilizadas para várias línguas. Rudemente falando, o character encoding fornece um mapeamento entre as coisas que você vê em sua tela e as coisas que o computador armazena na memória ou em disco.
Na realidade, é mais complicado que isso. O mesmo caracter pode aparecer em mais de uma codificação, mas cada uma pode usar uma sequência diferente de bytes para realmente armazenar o caracter em memória ou em disco. Então, você pode pensar no character encoding como um tipo de chave de decodificação para o texto. Sempre que alguém lhe der uma sequência de bytes e reivindicar seu “texto”, você precisa saber qual character encoding eles usaram, assim você pode decodificar os bytes em caracteres e exibí-los (ou processá-los, que seja).
Então, como seu browser determina o character encoding de um fluxo de bytes que um servidor web envia? Estou contente que perguntou. Se você está familiarizado com headers (cabeçalhos) HTTP, já deve ter visto um como esse:
Content-Type: text/html; charset="utf-8"
Brevemente, ele acha que o servidor web está lhe enviando um documento
HTML, e pensa que o documento usa o character encoding
UTF-8. Infelizmente, no magnífico mundo da World Wide Web,
poucos realmente tem controle sobre seus servidores HTTP. Pense no
Blogger: o conteúdo é fornecido
pelas pessoas, mas os servidores rodam pelo Google. Então o
HTML 4 fornecia uma maneira de especificar o character
encoding no prórpio documento HTML. Você provavelmente já
deve ter visto isso também:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Ele diz que o autor da página web pensa que criaram um documento
HTML usando o character encoding UTF-8.
Essas duas técnicas ainda funcionam no HTML5. O header
HTTP é o método preferido, e ele substitui a tag
<meta> se estiver presente. Mas não é qualquer um que
pode definir headers HTTP, então a tag
<meta> ainda está por aí. Na verdade, ficou um pouco
mais fácil no HTML5. Agora ela é assim.
<meta charset="utf-8" />
Isso funciona em todos os browsers. Como essa sintaxe abreviada apareceu? Aqui está a melhor explicação que consegui encontrar:
A lógica para a combinação do atributo
<meta charset="">é que UAs já implementam isso, pois as pessoas tendem a deixar as coisas sem áspas como:
<META HTTP-EQUIV=Content-Type CONTENT=text/html; charset=ISO-8859-1>
Há até alguns
casos de teste de <meta charset>
se você não acreditar que os browsers já fazem isso.
☞P: Eu nunca uso caracteres diferentes. Eu ainda preciso declarar meu character encoding?
R: Sim! Você deve sempre especificar um character encoding em toda página HTML que escreve. Não especificar um encoding pode levar a vulnerabilidades de segurança.
Resumindo: character encoding é complicado, e ele não foi feito de uma
maneira mais fácil devido a décadas de software mal escrito feito por
copia-e-cola. Você deve sempre especificar um character
encoding em todos os documentos HTML, ou
coisas ruins vão acontecer. Você pode fazer isso com o HTTP Content-Type header, com a
declaração <meta http-equiv>, ou com a declaração mais
curta <meta charset>, mas por favor faça. A web
agradece.
❧
Links normais (<a href>) simplesmente apontam para uma
outra página. Link relations são uma maneira de explicar o
por que você está apontando para uma outra página. Eles terminam
a frase “Estou apontando para esta outra página por que...”
E por aí vai. HTML5 separa os link relations em duas categorias:
Duas categorias de links podem ser criadas usando o elemento link. Links para recursos externos são links para recursos que são usados para extender o documento atual, e hyperlinks são links para outros documentos. ...
O comportamento exato para links de recursos externos depende da exata relação, como definido para o tipo de link relevante.
Dos exemplos que acabei de dar, somente o primeiro
(rel="stylesheet") é um link para um recurso externo. O resto
são hyperlinks para outros documentos. Você pode querer seguir esses
links, ou não, mas eles não são exigidos para ver a página atual.
Geralmente, link relations são vistos nos elementos
<link> dentro do elemento <head> de
uma página. Alguns podem também ser usados em elementos
<a>, mas isso é incomum mesmo quando permitido.
HTML5 também permite alguns relations em elementos
<area>, mais isso é até menos comum (HTML 4
não permitia um atributo rel nos elementos
<area>). Veja
a tabela completa de link relations
para verificar onde você pode usar valores específicos de
rel.
☞P: Posso criar meu próprio link relations?
R: Parece haver um suprimento infinito de idéias para novos link relations. Em uma tentativa para evitar que as pessoas façam besteira, o WHATWG mantém um registro das propostas para valores
rele define o processo para aceitá-las.
Vamos olhar o primeiro link relation em nossa página de exemplo:
<link rel="stylesheet" href="style-original.css" type="text/css" />
Este é o link relation mais usado no mundo (literalmente).
<link rel="stylesheet"> é para apontar para regras
CSS que estão armazenadas em um arquivo separado. Uma pequena
otimização que você pode fazer no HTML5 é retirar o atributo
type. Há somente uma linguagem stylesheet para a web,
o CSS, então esse é o valor padrão para o atributo
type. Isso funciona em todos os browsers. (Creio que alguem
pode inventar uma nova linguagem stylesheet algum dia, mas se acontecer,
apenas acrescente o atributo type de volta).
<link rel="stylesheet" href="style-original.css" />Continuando com nossa página de exemplo:
<link rel="alternate"
type="application/atom+xml"
title="My Weblog feed"
href="/feed/" />
Esse link relation também é bastante comum.
<link rel="alternate">, combinado com
RSS ou Atom media no atributo type, habilita
algo chamado “descoberta de feed”. Ele permite que leitores de feeds (como
Google Reader) descubram que
um site tem um feed de notícias dos últimos artigos. Alguns browsers
também suportam a descoberta de feed exibindo um ícone especial perto da
URL. (Ao contrário do rel="stylesheet", o
atributo type importa aqui. Não remova-o!)
O link relation rel="alternate" sempre foi um caso estranho
de uso,
até no HTML 4. No HTML5, sua definição foi clareada e extendida para
descrever o atual conteúdo da web mais cuidadosamente. Como você acabou de
ver, usando rel="alternate" em conjunto com
type=application/atom+xml indica um feed Atom para a página
atual. Mas você também pode usar o rel="alternate" em
conjunto com outros atributos type para indicar o mesmo
conteúdo em outro formato, como PDF.
HTML5 também encerrou uma confusão de longa data sobre como apontar para
documentos de tradução. HTML 4 diz para usar o atributo
lang em conjunto com rel="alternate" para
especificar a língua do documento apontado, mas isso é incorreto. O
documento
HTML 4 Errata
lista quatro erros na especificação do HTML 4. Um desses
erros é como especificar a língua de um documento apontado com
rel="alternate". A maneira correta, descrita no
HTML 4 Errata e agora no HTML5, é usar o
atributo hreflang. Infelizmente, essa errata nunca foi
reintegrada na especificação do HTML 4, por que ninguém mais
no W3C HTML Working Group estava trabalhando com
HTML.
rel="author" é usado para apontar para informações sobre o
autor da página. Pode ser um endereço mailto:, embora não
precise ser. Ele pode simplesmente levar a um formulário de contato ou a
uma página “sobre o autor”.
rel="external" “indica que o link trata-se de um documento que não faz parte do site em que o documento atual está.” Acredito que isso foi popularizado pela WordPress, a qual o utiliza nos links dos comentários deixados pelas pessoas.

HTML 4 usava
rel="start", rel="prev", e
rel="next"
para definir relações entre páginas que fazem parte de uma série (como
capítulos de um livro ou até posts de um blog). O único que era utilizado
corretamente era o rel="next". As pessoas usavam
rel="previous" ao invés de rel="prev"; usavam
rel="begin" e rel="first" ao invés de
rel="start"; utilizavam rel="end" invés de
rel="last". Oh, e — por conta própria — eles criaram
rel="up" para apontar para uma “página pai”.
HTML5 inclui rel="first", que é a variação mais
comum das diferentes maneiras para dizer “primeira página da série.”
(rel="start" é um sinônimo sem conformidade, fornecido para
compatibilidade.) Também inclui rel="prev" e
rel="next", igual ao HTML 4, e suporta
rel="previous" para compatibilidade, assim como
rel="last" (a última da série, começada por
rel="first") e rel="up".
A melhor maneira de pensar em rel="up" é olhar para sua
trilha de navegação (ou pelo menos imaginá-la). Sua página principal é
provavelmente a primeira página em sua trilha e a página atual está no
final. rel="up" aponta para a página seguinte a última página
da trilha.
rel="icon"
é o
segundo link relation mais popular, depois do rel="stylesheet". Ele é geralmente encontrado
junto ao shortcut, assim:
<link rel="shortcut icon" href="/favicon.ico">Todos os principais browsers suportam seu uso para associar um pequeno ícone a uma página. Geralmente é exibido na barra de endereço do browser próximo a URL, ou na aba do browser, ou em ambos.
Novo também no HTML5: os atributos sizes podem
ser usados em conjunto em um relacionamento com o ícone para
indicar o tamanho do ícone referenciado.
rel="license" foi inventado pela comunidade de microformatos. Ele “indica que o documento referenciado fornece os termos da licença sob o qual o documento atual é fornecido.”
rel="nofollow"
“indica que o link não foi aprovado pelo autor original ou publicador da
página, ou que o link para o documento referenciado foi incluído
inicialmente por causa de uma relação comercial entre pessoas afiliadas
com as duas páginas.” Isso foi
inventado pelo Google
e
padronizado dentro da comunidade de microformatos. WordPress adicionou
rel="nofollow" para links incluídos nos comentários. A idéia
era que se os links “nofollow” não aparecessem no PageRank, spammers
desistiriam de tentar postar spams nos comentários dos blogs. Isso não
aconteceu, mas rel="nofollow" ainda persiste.
rel="noreferrer" “indica que nenhuma informação de referência deve ser vazada quando clicar no link.” Atualmente nenhum browser suporta isso, mas o suporte foi adicionado pelo WebKit, sendo que ele aparecerá no Safari, Google Chrome, e outros WebKit browsers. [rel="noreferrer" test case]
rel="pingback" especifica o endereço de um servidor “pingback”. Como explicado na especificação do Pingback, “O sistema pingback é uma maneira de um blog ser notificado automaticamente quando outros sites chamarem um link para ele. ... Ele permite um vínculo reverso — um modo de voltar em uma corrente de links ao invés de somente fazer um drill down.” Sistemas de blogs, especialmente o WordPress, implementam o mecanismo de pingback para notificar os autores que você criou um link para a página deles quando criou um novo post em seu blog.

rel="prefetch"
“indica que buscar e armazenar um recurso especificado preventivamente é
provável que seja benéfico, como o usuário provavelmente irá exigir este
recurso.” Mecanismos de busca, às vezes, adicionam
<link rel="prefetch" href="URL do primeiro resultado da busca">
para a página de resultados da busca se eles sentem que o primeiro
resultado é freneticamente mais popular que qualquer um. Por exemplo:
usando Firefox,
procure CNN no Google,
olhe o código fonte, e procure pela palavra-chave prefetch.
Mozilla Firefox é o único browser atual que suporta
rel="prefetch".
rel="search"
“indica que o documento referenciado fornece uma interface específica para
procurar o documento e seus recursos relacionados.” Especificamente, se
você quer que o rel="search" faça algo útil, ele deve apontar
para um documento OpenSearch que
descreve como um browser poderia construir uma URL para procurar o site
atual para uma dada palavra-chave. OpenSearch (e
rel="search" ligam aquele ponto para documentos OpenSearch)
tem sido suportado no Microsoft Internet Explorer desde a versão 7 e no
Mozilla Firefox desde a versão 2.
rel="sidebar"
“indica que o documento referenciado, se recuperado, destina-se a ser
exibido em um contexto de navegação secundário (se possível), ao invés de
no mesmo contexto de navegação atual.” O que isso significa? No Opera e no
Mozilla Firefox, isso significa que “quando eu clicar neste link, é
solicitado ao usuário para criar um bookmark que, quando selecionado pelo
menu de Bookmarks, abre o documento vinculado em uma sidebar do browser.”
(Opera atualmente chama isso de “painel” ao invés de “sidebar.”) Internet
Explorer, Safari, e Chrome ignoram rel="sidebar" e apenas o
tratam como um link normal. [rel="sidebar" test case]
rel="tag"
“indica que a tag que o documento referenciado representa aplica-se ao
documento atual.” Marcação de “tags” (category keywords) com o atributo
rel foi
inventado pela Technorati
para ajuda-los a categorizar os posts do blog. Blogs antigos e tutoriais
assim se referiu a eles como “Technorati tags.” (Você leu certo: uma
empresa comercial convenceu o mundo todo a adicionar metadata que
facilitaram o trabalho da empresa. Belo trabalho se você pode te-lo!) A
sintaxe foi mais tarde
padronizada dentro da comunidade de microformatos, onde foi simplesmente chamada de rel="tag". A maioria de
sistemas de blog que permitem categorias associadas, palavras-chave, ou
tags com posts individuais vão marca-las com links rel="tag".
Os browsers não fazem nada de especial com eles; eles são realmente
desenhados para mecanismos de busca para usar como um sinal sobre do que a
página se trata.
❧
HTML5 não se trata somente em reduzir as marcações existentes (embora faça-o em uma quantidade razoável). Ele também define novos elementos semânticos.
<section>
section representa uma seção genérica de um
documento ou aplicação. Uma seção, neste contexto, é um agrupamento de
conteúdo, geralmente com um título. Exemplos de seções podem ser
capítulos, páginas em abas de uma caixa de diálogo, ou as seções
numeradas de uma tese. A página inicial de um website pode ser separada
em seções para introdução, itens de notícias, informações para contato.
<nav>
nav representa a seção de uma página que aponta
para outras páginas ou para partes dentro da página: uma seção com links
de navegação. Nem todos os grupos de links de uma página precisam estar
em um elemento nav — apenas seções que consistem em grandes
blocos de navegação são apropriados para o elemento nav.
Particularmente, é comum para rodapés (footers) possuir uma pequena
lista de links para páginas em comum de um site, tal como termos de uso,
página inicial e página de direitos autorais. O elemento
footer sozinho é suficiente para esses casos, sem o
elemento nav.
<article>
article representa um componente de uma página
que consiste em uma composição de conteúdo próprio em um documento,
página, aplicação, ou site e que destina-se a ser independentemente
distribuível ou reutilizável, e.g. in syndication. Pode ser uma postagem
em um fórum, um artigo de uma revista ou jornal, o comentário de um
usuário, um widget ou gadget interativo, ou qualquer outro item
independente de conteúdo.
<aside>
aside representa a seção de uma página que
consiste em conteúdo que é tangencialmente relacionado ao conteúdo em
torno do elemento aside, e o qual pode ser considerado
separado daquele conteúdo. Tais seções são frequentemente representadas
como barras laterias em tipografia impressa. O elemento pode ser usado
para efeitos tipográficos como citações e barras laterais, para
publicidade, para grupos de elementos nav, e para outro
conteúdo que é considerado separado do conteúdo principal da página.
<hgroup>
hgroup representa o título de uma seção. O
elemento é usado para agrupar um conjunto de elementos
h1–h6 quando o título possui vários níveis,
tais como subtítulos, títulos alternativos, ou slogans.
<header>
header representa um grupo de ajuda introdutória
ou navegação. Um elemento header geralmente pretende
possuir o título da seção (um elemento h1–h6
ou um elemento hgroup), mas isso não é obrigatório. O
elemento header também pode ser usado para cobrir uma seção
de tabelas de conteúdo, um formulário de busca, ou qualquer logo
relevante.
<footer>
footer representa um rodapé para a seção de
conteúdo mais próxima ou seção do elemento raiz. Um rodapé tipicamente
contém informação sobre sua seção tal como quem a escreveu, links para
documentos relacionados, declaração de direitos autorais, e assim por
diante. Os rodapés não precisam necessariamente aparecer no fim da
seção, embora eles geralmente apareçam. Quando o elemento
footer contém seções inteiras, eles representam apêndices,
índices, longos termos de uso, e outros conteúdos.
<time>
time representa tanto uma hora em um relógio de
24 horas, como uma data precisa no calendário gregoriano, opcionalmente
com uma hora e um fuso horário.
<mark>
mark representa a execução de texto em um
documento marcado ou destacado com o propósito de referência.
Eu sei que você está ansioso para começar a usar esses novos elementos, caso contrário você não estaria lendo este capítulo. Mas primeiro nós precisamos fazer um pequeno desvio.
❧
Todo browser tem uma lista de elementos HTML que suporta. Por exemplo, a lista do Mozilla Firefox está armazenada em nsElementTable.cpp. Elementos que não estão nesta lista são tratados como “elementos desconhecidos.” Há dois problemas fundamentais com elementos desconhecidos:
<p> tem espaçamento na parte superior e inferior,
<blockquote> é recuado com uma margem esquerda, e
<h1> é exibido em uma fonte maior. Mas quais estilos
padrão devem ser aplicados aos elementos desconhecidos?
nsElementTable.cpp do Mozilla inclui informações sobre
quais tipos de outros elementos cada um pode conter. Se você incluir
markup como <p><p>, o elemento do segundo
parágrafo implicitamente fecha o primeiro, assim os elementos terminam
como irmãos, e não pai e filho. Mas se você escrever
<p><span>, o span não fecha o
parágrafo, porque o Firefox sabe que <p> é um
elemento de bloco que pode conter o elemento de linha
<span>. Então, o <span> termina
como um filho do <p> no DOM.
Browsers diferentes respondem a essas perguntas de diferentes maneiras. (Revoltante, Eu sei). Dos principais browsers, a resposta do Microsoft Internet Explorer para as duas perguntas é a mais problemática, mas todo browser precisa de uma pequena ajuda aqui.
A primeira pergunta deveria ser relativamente simples de responder: Não aplique nenhum estilo especial para elementos desconhecidos. Apenas deixe-os herdar qualquer que seja as propriedades CSS que estão em vigor e onde quer que apareça, e deixe que o autor da página especifique todos os estilos com CSS. E isso funciona, com a maioria, mas há uma pequena pegadinha que você precisa estar ciente.
Todos os browsers apresentam elementos desconhecidos como elementos em linha, i.e. como se eles tivessem a regra
display:inlinede CSS.
Há diversos elementos novos definidos no HTML5 que são de
nível de bloco. Isto é, eles podem conter outros elementos com nível de
bloco, e os browsers compatíveis com o HTML5 irão aplicar a
propriedade display:block por padrão. Se você quiser utilizar
esses elementos em browsers antigos, precisará definir a propriedade
display manualmente:
article,aside,details,figcaption,figure,
footer,header,hgroup,menu,nav,section {
display:block;
}(Esse código é tirado de HTML5 Reset Stylesheet de Rich Clark, o qual faz muitas outras coisas além do escopo deste capítulo).
Mas espere, fica pior! Antes da versão 9, o Internet Explorer não aplicou qualquer estilo nos elementos desconhecidos. Por exemplo, se você tivesse essa implementação:
<style type="text/css">
article { display: block; border: 1px solid red }
</style>
...
<article>
<h1>Welcome to Initech</h1>
<p>This is your <span>first day</span>.</p>
</article>
O Internet Explorer (até a versão 8) não trata o elemento
<article> como um elemento de nível de bloco, nem
coloca uma borda vermelha em volta do article. Todas as regras de estilo
são simplesmente ignoradas.
O Internet Explorer 9 corrige este problema.
O segundo problema é o DOM que os browsers criam quando encontram elementos desconhecidos. Novamente, o browser mais problemático são as versões antigas do Internet Explorer (antes da versão 9, a qual corrige esse problema também). Se o IE 8 não reconhecer explicitamente o nome do elemento, ele irá inserir o elemento no DOM como um nó vazio sem filhos. Todos os elementos que você esperaria serem filhos diretos de um elemento desconhecido, na verdade estarão inseridos como irmãos do mesmo.
Aqui está uma arte ASCII para ilustrar a diferença. Este é o DOM que o HTML5 determina:
article | +--h1 (filho de article) | | | +--text node "Welcome to Initech" | +--p (filho de article, irmão de h1) | +--text node "This is your " | +--span | | | +--text node "first day" | +--text node "."
Mas esse é o DOM que o Internet Explorer atualmente cria:
article (sem filhos) h1 (irmão de article) | +--text node "Welcome to Initech" p (irmão de h1) | +--text node "This is your " | +--span | | | +--text node "first day" | +--text node "."
Existe uma maravilhosa solução alternativa para este problema. Se você
criar um elemento <article> falso
com JavaScript antes de usá-lo na página, o Internet Explorer irá
magicamente reconhecer o elemento <article> e deixar
você aplicar um estilo CSS nele. Não há necessidade de inserir o elemento
falso dentro do DOM. Simplesmente criar o elemento uma vez
(por página) é o suficiente para ensinar o IE como aplicar estilo ao
elemento que ele não reconhece.
<html>
<head>
<style>
article { display: block; border: 1px solid red }
</style>
<script>document.createElement("article");</script>
</head>
<body>
<article>
<h1>Welcome to Initech</h1>
<p>This is your <span>first day</span>.</p>
</article>
</body>
</html>Isso funciona em todas as versões do Internet Explorer, até o IE 6! Nós podemos extender essa técnica para criar cópias falsas de todos os novos elementos do HTML5 agora mesmo — novamente, eles nunca são inseridos no DOM, sendo que você nunca verá esses elementos falsos — e apenas começar usá-los sem se preocupar muito com os browsers não compatíveis com o HTML5.
Remy Sharp fez justamente isso, com seu acertadamente chamado HTML5 enabling script. Esse script passou por mais de uma dúzia de revisões desde quando comecei a escrever este livro, mas a idéia é basicamente esta:
<!--[if lt IE 9]>
<script>
var e = ("abbr,article,aside,audio,canvas,datalist,details," +
"figure,footer,header,hgroup,mark,menu,meter,nav,output," +
"progress,section,time,video").split(',');
for (var i = 0; i < e.length; i++) {
document.createElement(e[i]);
}
</script>
<![endif]-->
Os trechos <!--[if lt IE 9]> e
<![endif]--> são
comentários condicionais. O Internet Explorer os interpreta como um if: “se o
browser atual é uma versão do Internet Explorer anterior a versão 9, então
executa este bloco.” Qualquer outro browser irá tratar todo o bloco como
um comentário HTML. O resultado é que o Internet Explorer
(até e incluindo a versão 8) executará este script, mas os outros browsers
irão ignorar este script completamente. Isso faz sua página carregar mais
rápido em browsers que não precisam deste hack.
O código JavaScript é relativamente simples. A variável
e termina como um array de strings como "abbr",
"article", "aside", e assim por diante. Depois
percorremos o array e criamos cada elemento nomeado chamando
document.createElement(). Mas uma vez que ignoramos o valor
de retorno, os elementos nunca são inseridos dentro do DOM.
Mas é o suficiente para o Internet Explorer tratar esses elementos do
jeito que queremos que sejam tratados, uma vez que os usamos mais tarde na
página.
Este trecho “mais tarde” é importante. Este script precisa estar no topo
de sua página, preferencialmente em seu elemento
<head>, e não no final. Dessa forma, o Internet
Explorer irá executar este script antes de analisar suas tags e
atributos. Se você colocar este script no final de sua página, ele o
executará tarde. O Internet Explorer já terá mal interpretado sua
implementação e construído o DOM errado, e não voltará para
ajustá-lo por causa desse script.
Remy Sharp “minificou” este script e o hospedou no Google Project Hosting. (Para o caso de estar se perguntando, o script é open source e possui licença MIT, então pode ser usado em qualquer projeto.) Se preferir, você pode até “linkar” o script apontando diretamente para a versão hospedada, assim:
<head>
<meta charset="utf-8" />
<title>My Weblog</title>
<!--[if lt IE 9]>
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
</head>Agora estamos prontos para começar a usar os novos elementos no HTML5.
❧

Vamos voltar para nossa página de exemplo. Especificamente, vamos olhar apenas para os headers:
<div id="header">
<h1>My Weblog</h1>
<p class="tagline">A lot of effort went into making this effortless.</p>
</div>
…
<div class="entry">
<h2>Travel day</h2>
</div>
…
<div class="entry">
<h2>I'm going to Prague!</h2>
</div>Não há nada de errado com essa implementação. Se preferir, você pode mantê-la. É válido no HTML5. Mas o HTML5 provê alguns elementos adicionais para headers e sections.
Primeiramente, vamos nos livrar daquele
<div id="header">. Esse é um padrão comum, mas isso não
significa nada. O elemento div não possui uma semântica
definida, e o atributo id também não. (User agents não têm
permissão para inferir qualquer significado do valor do atributo
id). Você pode mudar isso para
<div id="shazbot"> e ele terá o mesmo valor semântico,
i.e., nenhum.
HTML5 define um elemento <header> para
este propósito. A especificação do HTML5 possui
exemplos reais do uso do elemento <header>. Aqui está como ficaria parecido em
nossa página de exemplo:
<header>
<h1>My Weblog</h1>
<p class="tagline">A lot of effort went into making this effortless.</p>
…
</header>Isso é legal. Ele diz para quem quiser saber que este é o header. Mas e aquela tagline? Outro padrão comum, que até agora não tinha implementação padrão. É uma coisa difícil de implementar. Uma tagline é como um subtítulo, mas está “ligado” ao título principal. Isso é, é um subtítulo que não cria sua própria section.
Elementos Header como <h1> e
<h2> dão estrutura para sua página. Juntos, eles criam
um esboço que você pode usar para visualizar (ou navegar) em sua página.
Leitores de tela usam esboços de documentos para ajudar usuários cegos a
navegar por sua página. Existem
ferramentas online e
extensões de browsers
que ajudam a visualizar o esboço de seu documento.
No HTML 4, os elementos <h1>–<h6>
são a única maneira de criar um esboço do documento. O esboço da
página de exemplo se parece com isso:
My Weblog (h1) | +--Travel day (h2) | +--I'm going to Prague! (h2)
Tudo bem, mas quer dizer que não tem como implementar a tagline “Um grande
esforço foi feito para reduzir o esforço.” Se tentássemos implementá-lo
como um <h2>, ele iria adicionar um nó fantasma ao
esboço do documento:
My Weblog (h1) | +--A lot of effort went into making this effortless. (h2) | +--Travel day (h2) | +--I'm going to Prague! (h2)
Mas essa não é a estrutura do documento. A tagline não representa uma section, é apenas um subtítulo.
Talvez nós poderiamos implementar a tagline como um
<h2> e marcar cada título de artigo como um
<h3>? Não, é até pior:
My Weblog (h1)
|
+--A lot of effort went into making this effortless. (h2)
|
+--Travel day (h3)
|
+--I'm going to Prague! (h3)
Agora nós ainda temos um nó fantasma no esboço de nosso documento, mas ele
“roubou” os filhos que legitimamente pertencem ao nó raiz. E aqui reside o
problema: HTML 4 não fornece uma maneira de implementar um
subtítulo sem adicioná-lo ao esboço do documento. Não importa o quanto
tentarmos mudar as coisas, “um grande esforço feito para reduzir o
esforço” terminará naquele gráfico. Esse é o porque acabamos com marcações
semânticas sem significado como <p class="tagline">.
HTML5 fornece uma solução para isso: o elemento
<hgroup>. O elemento <hgroup> atua
como um empacotador para dois ou mais elementos de título
relacionados. O que quer dizer “relacionados”? Significa que
juntos, eles criam um único nó no esboço do documento.
Dada esta implementação:
<header>
<hgroup>
<h1>My Weblog</h1>
<h2>A lot of effort went into making this effortless.</h2>
</hgroup>
…
</header>
…
<div class="entry">
<h2>Travel day</h2>
</div>
…
<div class="entry">
<h2>I'm going to Prague!</h2>
</div>Esse é o esboço do documento que é criado:
My Weblog (h1 of its hgroup) | +--Travel day (h2) | +--I'm going to Prague! (h2)
Você pode testar suas próprias páginas no HTML5 Outliner para garantir que você está usando os elementos de título corretamente.
❧
Continuando com nossa página de exemplo, vamos ver o que podemos fazer sobre esta implementação:
<div class="entry">
<p class="post-date">October 22, 2009</p>
<h2>
<a href="#"
rel="bookmark"
title="link to this post">
Travel day
</a>
</h2>
…
</div>
Novamente, isto é HTML5 válido. Mas o
HTML5 fornece elementos mais específicos para o caso comum de
implementação de um artigo em uma página — chamado apropriadamente de
<article>.
<article>
<p class="post-date">October 22, 2009</p>
<h2>
<a href="#"
rel="bookmark"
title="link to this post">
Travel day
</a>
</h2>
…
</article>Ah, mas não é tão simples assim. Há mais uma mudança que você deve fazer. Vou lhe mostrar primeiro, depois eu explico:
<article>
<header>
<p class="post-date">October 22, 2009</p>
<h1>
<a href="#"
rel="bookmark"
title="link to this post">
Travel day
</a>
</h1>
</header>
…
</article>
Você entendeu isso? Eu mudei o elemento <h2> para um
elemento <h1>, e o coloquei dentro de um elemento
<header>. Você já viu o elemento
<header> em ação. Seu propósito é envolver todos os
elementos que formam o cabeçalho do artigo (neste caso, a data de
publicação e título do artigo). Mas…mas…mas… não deveríamos ter apenas um
<h1> por documento? Isso não vai estragar o esboço do
documento? Não, mas para entender porque não, nós precisamos dar um passo
para trás.
No HTML 4, a única maneira de criar um esboço do
documento era com os elementos
<h1>–<h6>. Se você apenas quisesse
um nó raiz em seu esboço, você tinha que limitar-se a um
<h1> em sua implementação. Mas a especificação do
HTML5
define um algoritmo para gerar um esboço de documento
que incorpora os novos elementos semânticos no HTML5. O
algoritmo do HTML5 diz que um elemento
<article> cria uma nova seção, que é, um novo nó no
esboço do documento. E no HTML5, cada seção pode possuir seu
próprio elemento <h1>.
Esta é uma mudança drástica do HTML 4, e aqui está o porque isso é uma coisa boa. Muitas páginas da web são realmente geradas por templates. Um pouco de conteúdo é tirado de uma fonte e inserido na página aqui; um pouco de conteúdo é tirado de outra fonte e inserido na página ali. Muitos tutoriais são estruturados da mesma maneira. “Aqui está uma implementação HTML. Apenas copie e cole em sua página.” Tudo bem para pequenos trechos de conteúdo, mas e se a implementação que você está colando é uma seção inteira? Neste caso, o tutorial vai estar como algo do tipo: “Aqui está uma implementação HTML. Apenas copie e cole em seu editor de texto, e corrija as tags de cabeçalho para que possam coincidir com o nível de aninhamento das tags correspondentes da página em que você o está colando.
Deixe-me colocar isso de outra forma. HTML 4 não possui um
elemento de cabeçalho genérico. Ele possui seis elementos
estritamente numerados, <h1>–<h6>,
os quais têm que estar exatamente nesta ordem. Este tipo de coisa fede,
especialmente se sua página é “montada” ao invés de “criada.” E este é o
problema que o HTML5 resolve com os novos elementos de seção
e as novas regras para os elementos de cabeçalho existentes. Se você está
usando os novos elementos de seção, posso lhe dar esta implementação:
<article>
<header>
<h1>A syndicated post</h1>
</header>
<p>Lorem ipsum blah blah…</p>
</article>
e você pode copiar e colar em qualquer lugar de sua página sem
modificação. O fato de ele conter um elemento <h1> não
é um problema, porque a coisa toda está contida dentro de um
<article>. O elemento
<article> define um nó contido em si próprio no esboço
do documento, o elemento <h1> fornece o título para
aquele nó, e todos os outros elementos de seção da página vão permanecer
em qualquer nível de aninhamento que se encontravam antes.
Como todas as coisas na web, a realidade é um pouco mais complicada do que estou mostrando. Os novos elementos de seção “explícitos” (como
<h1>contido no<article>) podem interagir de inesperadas maneiras com os velhos elementos “implícitos” (<h1>–<h6>). Sua vida ficará mais simples se você usar um ou outro, mas não os dois. Se você precisar usar os dois na mesma página, tenha certeza de checar o resultado em HTML5 Outliner e verifique se o esboço de seu documento faz sentido.
❧

Isso é emocionante, não é? Digo, não é como “esquiar pelado no Mount Everest enquanto recita o Star Spangled Banner de trás pra frente”, mas é bem emocionante o quão longe a marcação semântica vai. Vamos continuar com nossa página de exemplo. A próxima linha que quero destacar é esta:
<div class="entry">
<p class="post-date">October 22, 2009</p>
<h2>Travel day</h2>
</div>
A mesma velha estória, certo? Um padrão comum — designando a data de
publicação de um artigo — que não contém marcação semântica para apoiá-lo,
então autores recorrem às implementações genéricas com alterações em
atributos de class. Novamente, isso é
HTML5 válido. Você não é obrigado a mudar isso. Mas
o HTML5 fornece uma solução específica para este caso: o
elemento <time>.
<time datetime="2009-10-22" pubdate>October 22, 2009</time>Há três partes no elemento <time>:
pubdate
Neste exemplo, o atributo datetime apenas especifica a data,
não o tempo. O formato é de quatro dígitos para o ano, dois dígitos para o
mês, e dois dígitos para o dia, separado por traços:
<time datetime="2009-10-22" pubdate>October 22, 2009</time>
Se você quiser incluir o tempo também, adicione a letra
T após a data, o tempo no formato de 24 horas, depois a
diferença da timezone.
<time datetime="2009-10-22T13:59:47-04:00" pubdate>
October 22, 2009 1:59pm EDT
</time>(O formato data/tempo é bastante flexível. A especificação do HTML5 contém exemplos de data/tempo válidas.)
Note que mudei o texto — entre <time> e
</time> — para combinar com a máquina de leitura para
timestamp. Isso não é obrigatório. O conteúdo pode ser o que você quiser,
contanto que você forneça uma máquina de leitura para data/timestamp no
atributo datetime. Então isso é HTML5 válido:
<time datetime="2009-10-22">last Thursday</time>E isso também é HTML5 válido:
<time datetime="2009-10-22"></time>
A peça final do quebra-cabeça é o atributo pubdate. É um
atributo Boolean, então apenas adicione-o se precisar, assim:
<time datetime="2009-10-22" pubdate>October 22, 2009</time>Se você não gostar de atributos “pelados”, isso é equivalente:
<time datetime="2009-10-22" pubdate="pubdate">October 22, 2009</time>
O que significa o atributo pubdate? Significa uma de duas
coisas. Se o elemento <time> está em um elemento
<article>, significa que este timestamp é a data de
publicação do artigo. Se o elemento <time> não está em
um elemento <article>, significa que esse timestamp é a
data de publicação do documento inteiro.
Este é o artigo inteiro, reformulado para tirar total vantagem do HTML5:
<article>
<header>
<time datetime="2009-10-22" pubdate>
October 22, 2009
</time>
<h1>
<a href="#"
rel="bookmark"
title="link to this post">
Travel day
</a>
</h1>
</header>
<p>Lorem ipsum dolor sit amet…</p>
</article>❧
Uma das partes mais importantes de qualquer site é a barra de navegação. A CNN.com tem “abas” ao longo do topo de cada página que apontam para diferentes seções de notícias — “Tech,” “Health,” “Sports,” &c. As páginas de resultado da busca do Google têm uma faixa semelhante no topo da página para tentar realizar sua busca em diferentes serviços do Google — “Imagens,” “Videos,” “Mapas,” &c. E nossa página de exemplo possui uma barra de navegação no cabeçalho que inclui links para diferentes seções de nosso hipotético site — “home,” “blog,” “gallery,” e “about.”
Assim é como a barra de navegação era originalmente implementada:
<div id="nav">
<ul>
<li><a href="#">home</a></li>
<li><a href="#">blog</a></li>
<li><a href="#">gallery</a></li>
<li><a href="#">about</a></li>
</ul>
</div>Novamente, isso é HTML5 válido. Mas enquanto é feito como uma lista de quatro itens, não há nada sobre a lista que lhe diga que ela faz parte da navegação do site. Visualmente, você pode adivinhar pelo fato dela fazer parte do cabeçalho da página, e pelo texto dos links. Mas semanticamente, não há nada para distinguir a lista de links de qualquer outra.
Quem liga para a semântica de navegação do site? Por exemplo, pessoas com deficiências. Por que isso? Considere este cenário: seu movimento é limitado, e usar o mouse é difícil ou impossível. Para compensar, você pode usar um componente do browser que lhe permite avançar para a maioria dos links de navegação. Ou considere isso: se sua visão é limitada, você pode usar um programa dedicado chamado “leitor de tela” que usa text-to-speech para falar e resumir as páginas da web. Uma vez que passar do título da página, os próximos trechos importantes de informação sobre uma página são os principais links de navegação. Se você quer navegar rápido, você dirá ao seu leitor de tela para pular para a barra de navegação e começar a ler. Se você quiser consultar rápido, você pode dizer ao seu leitor de tela para pular a barra de navegação e começar a ler o conteúdo principal. De qualquer forma, ser capaz de determinar os links de navegação programaticamente é importante.
Então, enquanto não há nada de errado em usar
<div id="nav"> para criar a navegação de seu site,
Também não há particularmente nada certo sobre isso. O
HTML5 fornece uma maneira semântica para implementar seções
de navegação: o elemento <nav>.
<nav>
<ul>
<li><a href="#">home</a></li>
<li><a href="#">blog</a></li>
<li><a href="#">gallery</a></li>
<li><a href="#">about</a></li>
</ul>
</nav>☞P: Há skip links compatíveis com o elemento
<nav>? Eu ainda preciso de skip links no HTML5?
R: Skip links permitem os leitores pularem entre as seções de navegação. Eles são úteis para usuários com deficiência que usam software de terceiros para ler uma página da web e navegar nela sem mouse. (Aprenda como e porque fornecer os skip links.)
Uma vez que os leitores de tela forem atualizados para reconhecer o elemento
<nav>, os skip links ficarão obsoletos, desde que o software de leitor de tela esteja apto a automaticamente saltar sobre uma seção de navegação implementada com o elemento<nav>. Contudo, isso será um pouco antes de todos os usuários com deficiência da web atualizarem para o software de leitor de tela com HTML5, então você deve continuar fornecendo seus próprios skip links para saltarem sobre as seções<nav>.
❧
Finalmente, nós chegamos ao fim de nossa página de exemplo. A última coisa sobre qual quero falar é a última coisa da página: o footer. O footer era originalmente implementado assim:
<div id="footer">
<p>§</p>
<p>© 2001–9 <a href="#">Mark Pilgrim</a></p>
</div>
Isso é HTML5 válido. Se você gostar, pode continuar com ele.
Mas o HTML5 fornece um elemento mais específico para isso: o
elemento <footer>.
<footer>
<p>§</p>
<p>© 2001–9 <a href="#">Mark Pilgrim</a></p>
</footer>
O que é apropriado colocar em um elemento <footer>?
Provavelmente qualquer coisa que você estiver colocando agora em um
<div id="footer">. OK, é uma resposta redundante. Mas
sério, é isso. A especificação do HTML5 diz, “Um footer
geralmente contém informação sobre sua seção como quem a escreveu, links
para documentos relacionados, copyright, e assim por diante.” É o que há
em nossa página de exemplo: declaração de copyright e um link para uma
página de "Sobre o autor". Olhando ao redor em alguns sites populares,
vejo muito potencial nos footers.
<footer>.
<footer>.
<footer>.
(Note que os links não devem ser incluídos em um elemento
<nav>, porque eles não são links de navegação do
site; eles são apenas uma coleção de links para meus outros projetos em
outros sites).
“Footers gordos” são raivosos hoje em dia. Dê uma olhada no footer do site da W3C. Ele contém três colunas, rotuladas “Navigation,” “Contact W3C,” e “W3C Updates.” A implementação se parece mais ou menos com isso:
<div id="w3c_footer">
<div class="w3c_footer-nav">
<h3>Navigation</h3>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>Contact W3C</h3>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>W3C Updates</h3>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</div>
<p class="copyright">Copyright © 2009 W3C</p>
</div>Para converter isso para HTML5 semântico, Eu faria as seguintes alterações:
<div id="w3c_footer"> externo para um
elemento <footer>.
<div class="w3c_footer-nav"> para elementos
<nav>, e a terceira instância para um elemento
<section>.
<h3> para <h1>, desde
que cada um ficará dentro de um elemento de seção. O elemento
<nav> cria uma seção no esboço do documento, assim
como o elemento
<article>.
A implementação final pode parecer como algo do tipo:
<footer>
<nav>
<h1>Navigation</h1>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</nav>
<nav>
<h1>Contact W3C</h1>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</nav>
<section>
<h1>W3C Updates</h1>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</section>
<p class="copyright">Copyright © 2009 W3C</p>
</footer>❧
Páginas de exemplo usadas em todo este capítulo:
Sobre codificação de caracteres:
Sobre permitir novo HTML5 no Internet Explorer:
Sobre modos padrões e doctype:
Validador HTML5:
❧
Este foi o “O que significa tudo isso?”. Consulte o Sumário, caso queira continuar com a leitura.
Em associação com o Google Press, O’Reilly está distribuindo este livro em uma variedade de formatos, incluindo papel, ePub, Mobi, e DRM-de graça PDF. A edição paga é chamada de “HTML5: Up & Running,” e está disponível agora. Este capítulo está incluído na edição paga.
Se você gostou deste capítulo e quer demonstrar sua apreciação, você pode comprar “HTML5: Up & Running” com este link afiliado ou comprar a edição eletrônica diretamente da O’Reilly. Você terá um livro, e eu um dinheirinho. Eu não estou aceitando doações diretas.
Copyright MMIX–MMXI Mark Pilgrim
{kind=link}